-2.png?width=156&height=60&name=Hawkin%20Logo%20(2)-2.png)
Who Owns Your Data?
.png?width=492&name=Cloud1-dayOut_TWITTER%20(2).png)

In sports performance technology, at all levels, who owns the data is an essential question to ask, and one that is often unanswered or poorly answered at best. Whose responsibility is it to ensure that athlete data is stored securely, protected, and not misused for whatever purpose? Is it the teams who utilize the technology? The athletes themselves? Or, is it the companies that produce and maintain the technology used in sport that should be taking the lead of data ownership?
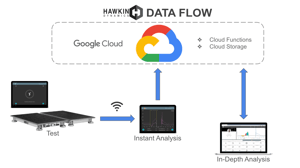
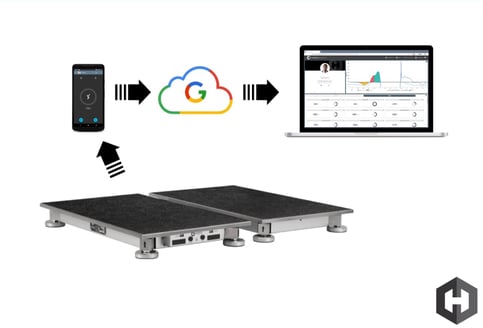
In any data model, there is a certain amount of responsibility on any party who is interacting with that data. A cloud system (or a local computer) is, of course, only as secure as the person operating it. That being said, at the most basic level, the ownership of the data in question should never be confusing or obfuscated. As a technology company that works with many world-class organizations, we believe that user data is and always should be owned by the user. Even if a client leaves our ecosystem, their data is never compromised, used, or rolled into a larger data set. This brings the question as to how we can tap-into the massive volume of data our system handles every day. The answer is clear, from our perspective. If we want to use data (including customer data) for ANY purpose beyond simple support questions where we may need to deal with their data to resolve issues or answer questions, we need explicit written permission and extremely detailed parameters under which we can utilize said data. This ensures that we are never in a position and that our users are never in a position where the ownership or integrity of their data can be questioned. It is also standard practice for us to anonymize any user data in the above-mentioned theoretical scenario, to ensure that personally identifiable information is not in our possession.
We believe that companies should be proactive about data ownership in their customer agreements and licenses. While it would be interesting to have a global data set of everyone who uses Hawkin Dynamics software, it's not really that useful for a few reasons. For one, we don't have the detail and context on any of the raw data - as the saying goes, bad data in = bad data out. Secondly, our users vary from middle-school educators to professional and Olympic athletes. How much value can really be gained from lumping these data sets together? Lastly, we didn't build our company on the promise that we could magically deploy "AI" to automatically detect specific injuries or potentially prevent any. We have built our company around a few simple values: transparency, scientific validity, customer service, and super slick cutting-edge technology. This includes AI modeling, which we are working on at the moment, but as always we want to be sure we have clear objectives when using this type of modeling rather than simply deploy it to say we use it.
